DrEvalPy: Python Cancer Cell Line Drug Response Prediction Suite




![]()
![]()
![]()
![]()
![]()
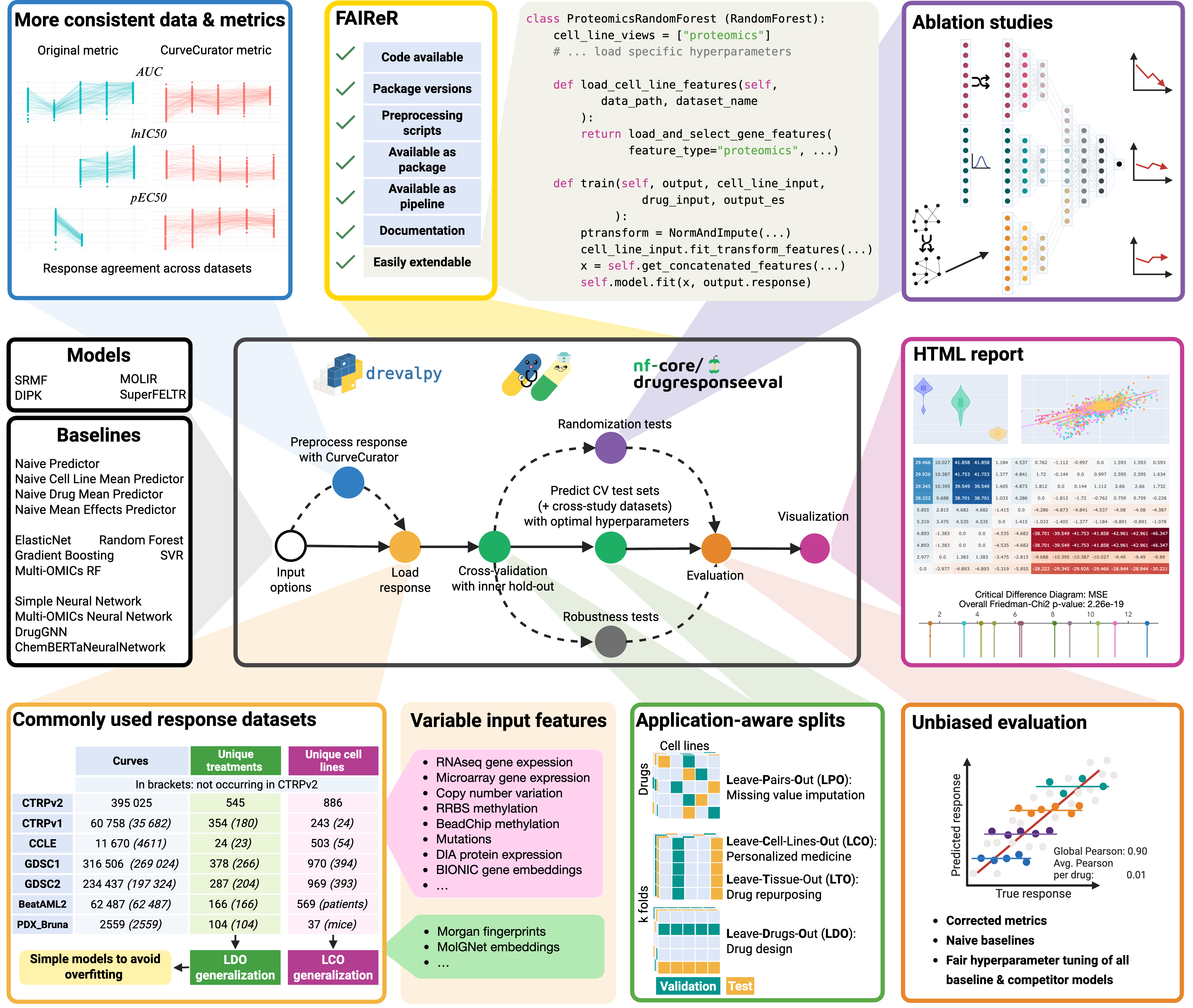
Overview
Check out our paper on Nature Communications!
Focus on Innovating Your Models — DrEval Handles the Rest!
DrEval is a toolkit that ensures drug response prediction evaluations are statistically sound, biologically meaningful, and reproducible.
Focus on model innovation while using our automated standardized evaluation protocols and preprocessing workflows.
A flexible model interface supports all model types (e.g. machine learning, statistical models, network-based analyses).
Use DrEval to build drug response models that have an impact
Maintained, up-to-date baseline catalog, no need to re-implement literature models
Gold standard datasets for benchmarking
Consistent application-driven evaluation
Ablation studies with permutation tests
Cross-study evaluation for generalization analysis
Optimized nextflow pipeline for fast experiments
Easy-to-use hyperparameter tuning
Paper-ready visualizations to display performance
This project is a collaboration of the Technical University of Munich (TUM, Germany) and the Freie Universität Berlin (FU, Germany).
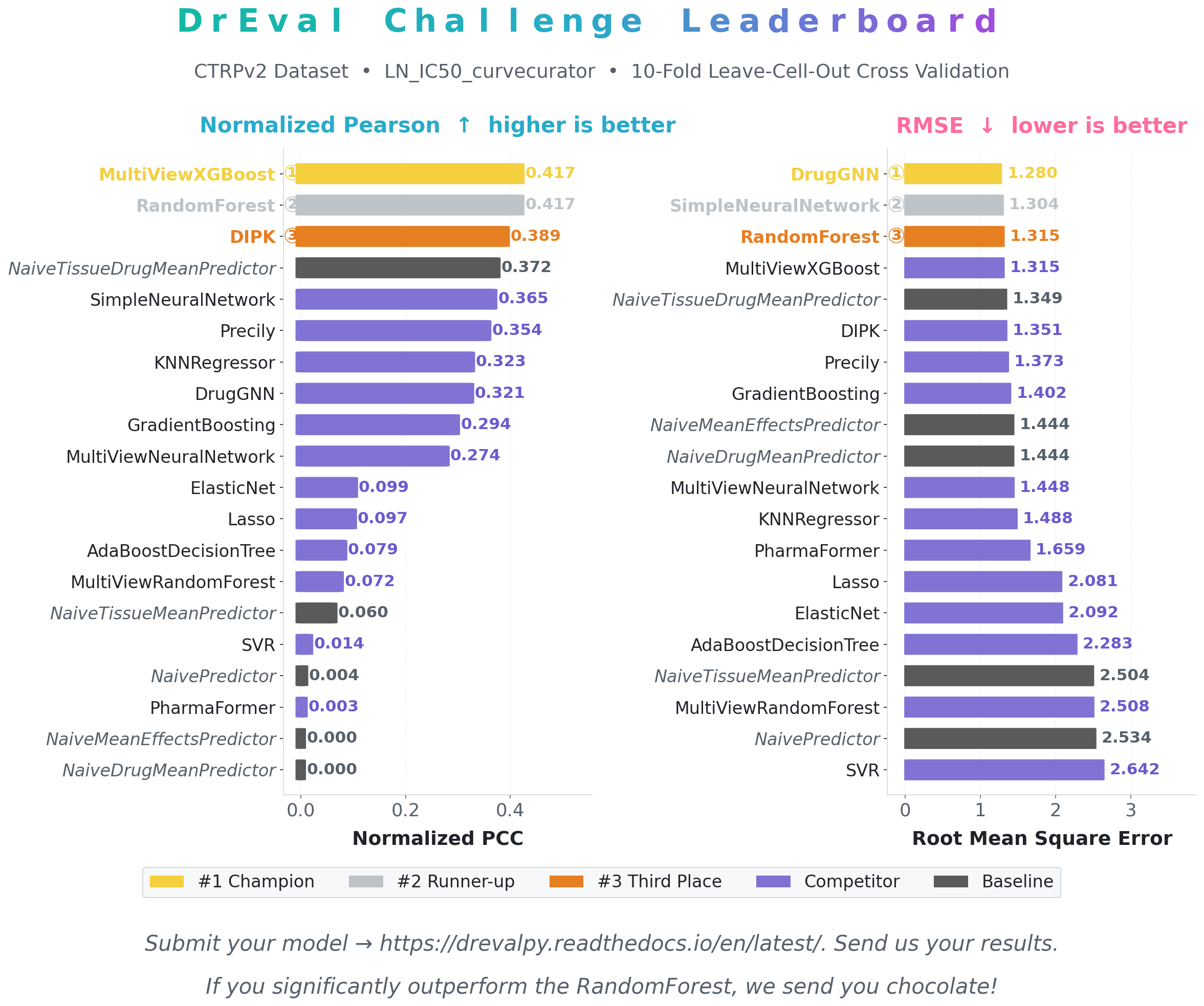
Leaderboard
Quickstart
Make sure you have installed DrEvalPy and its dependencies (see Installation).
To make sure the pipeline runs, you can use the fast models NaiveMeanEffectsPredictor and NaiveDrugMeanPredictor on the TOYv1 (subset of CTRPv2) or TOYv2 (subset of GDSC2) dataset with the LCO test mode.
drevalpy --run_id my_first_run --models NaiveTissueMeanPredictor NaiveDrugMeanPredictor --baselines NaiveMeanEffectsPredictor --dataset TOYv1 --test_mode LCO
This will train the three baseline models to predict LN_IC50 values of our Toy dataset which is a subset of CTRPv2. It will evaluate in “LCO” which is the leave-cell-line-out splitting strategy (leave random cell lines out for testing) using 7 fold cross validation. The results will be stored in
results/my_first_run/TOYv1/LCO
You can visualize them using
drevalpy report --run_id my_first_run --dataset TOYv1
This creates an index.html file which you can open in your browser to see the results of your run.
We recommend the use of our nextflow pipeline for computational demanding runs and for improved reproducibility. No knowledge of nextflow is required to run it. The nextflow pipeline is available on the nf-core GitHub, the documentation can be found here.
Want to test if your own model outperforms the baselines? See Run Your Model.
Discuss usage, development and issues on GitHub.
Check the Contributor Guide if you want to participate in developing.
If you use drevalpy for your work, please cite us.
News
📄 Our paper is finally published! 2026-05-12
After a long, long journey, our paper is finally published at Nature Communications! You can now officially cite us with:
Note
Critical evaluation of drug response prediction models with DrEval. Judith Bernett, Pascal Iversen, Mario Picciani, Mathias Wilhelm, Katharina Baum, Markus List. Nat Commun 17, 4238 (2026); doi: https://doi.org/10.1038/s41467-026-72903-w
📄 Our preprint is out! 2025-05-29
Check out our preprint on bioRxiv!
Note
From Hype to Health Check: Critical Evaluation of Drug Response Prediction Models with DrEval. Judith Bernett, Pascal Iversen, Mario Picciani, Mathias Wilhelm, Katharina Baum, Markus List. bioRxiv 2025.05.26.655288; doi: https://doi.org/10.1101/2025.05.26.655288
🚀 We have launched the DrEval Challenge 🚀 2024-11-26
📜 Origin Story 💊 2023-11-20
Long ago, the people of science lived in harmony. Researchers collaborated, data flowed freely, and models were tested with integrity. But then, the H-Index Nation attacked. Suddenly, impact factors ruled all, flashy results overshadowed rigorous testing, and biased benchmarks spread like wildfire. Science, once a beacon of knowledge, became clouded by competition and questionable practices. Only a fair and unbiased framework could restore balance. And when the field needed it most—drevalpy was born. A framework designed to test drug response prediction models with fairness and transparency, cutting through bias and restoring the integrity of scientific evaluation. Though the fight against bad practices is long, with drevalpy, balance may yet be restored.
Maintainers and Lead Contributors
Judith Bernett: TUM / FAU Erlangen-Nürnberg
Pascal Iversen: FU Berlin / Hasso-Plattner-Institut
Contributors
Mario Picciani: TUM, contributed to the curve fitting procedure and CI/CD.
Nico Trummer: Orakl Oncology/ TUM, contributed the NaiveTissueDrugMeanPredictor, integrated the PharmaFormer model, the wandb support, and the typer CLI.
Jonah Reiner: FU Berlin, supported the integration of the DIPK model.
Vera Tereshchuk: FU Berlin, integrated XGBoost and Precily.
Elena Sophie Dederer & Gregor Chojetzki: FU Berlin, integrated the KNNRegressor.
Greta Agnes Gulden & Larissa Susanka Koß: FU Berlin, integrated Lasso.
Matvej Elkonin: FU Berlin, integrated the AdaBoostDecisionTree.
Advisors and Principal Investigators
Markus List: Advisor and PI of Data Science in Systems Biology, TUM
Katharina Baum: Advisor and PI of Data Integration in the Life Sciences, FU Berlin
Mathias Wilhelm: Advisor and PI of Computational Mass Spectrometry, TUM